Complex Mainframe Migration: Data Migration
- Kelly DeMont, Robyn Fulton, & Bhaskar Kapa
- 9 min read
This post is the second in a series about the Ally Auto Advantage program, which was a strategic, multi-year initiative to modernize the core platform supporting our auto finance retail portfolio.Data Migration is the process of transferring large volumes of data from a legacy application or system of record (SOR) to a new SOR based on defined business requirements. In this post, we’ll talk about the role Data Migration played in Ally’s transition from our legacy mainframe application to a modern, web-based technology platform. Whether you’re considering a core platform replacement, like we undertook, or planning a smaller system re-factor, we hope you find our experience and lessons learned useful.
Why migrate data?
As part of the deployment of the Ally Auto Advantage core platform, we needed to migrate data from our legacy system to the new core servicing platform. The scope of data includes information about Ally Auto’s customers (like their names, addresses, and Social Security numbers), contracts details like rate, term, and loan amount, and data on our dealers and other third parties, such as auction houses and repossession companies. At the outset, we defined several objectives for the data migration process, including:
Maintaining quality, integrity, and security of the data through migration
Enabling the transformation from an account-centric structure to customer-centric data model
Optimizing the migration process to minimize the total system downtime
Engineering a solution meeting these objectives required a detailed understanding of several questions, including:
What data is needed to service our customers on the Advantage platform?
Where did that data exist?
What was the profile of the data (volume, quality, values, etc.)?
What transformation would be needed to correctly apply the data to the Advantage platform?
Which other systems would need updates after migration?
What methods of reconciliation would be required to have confidence in the data?
We’re going to share how we answered these questions and addressed other complexities to achieve our goals.
Migration Scope
After conducting extensive analysis, we were able to clearly define the scope of the data migration, making necessary refinements along the way. The effort was a “many-to-many” migration in which data was migrated from eight source systems to two primary targets and six secondary ones which received data further downstream, hosted in several different locations. All told, we moved 4.5TB of data, comprised of:
$80+ billion dollar asset portfolio
6.5 million customer records
4.6 million customer contracts
25 thousand dealer records
30 thousand non-customer entities, such as repossession vendors and auction houses
In addition to the sheer volume, the data migration also had many other complexities. Here are a few examples of the things we had to solve for:
1) Dynamic data — Clearly, the customer and account data being migrated wasn’t static. Here’s just one example: Ally processes more than 200,000 payment transactions daily. We had to capture the data at a point in time (in this case, exactly at year-end) and complete the migration and reconciliation steps before any transactions could be processed in the new system. The dynamic nature of the data also made it difficult to plan and practice the reconciliation: the data changed so much from month to month that we encountered new scenarios and nuances each time.
2) Decimal Handling — The legacy mainframe system truncated decimals while our new application rounded them. We had to develop a method to adjust accounts as they migrated to ensure that account balances transferred correctly.
3) Account Conversion — To accommodate differences between our old and new systems, we needed to rebuild each contract in the new system, based on the original contract terms, such as inception date, amount financed, rate, and length of contract. This ensured that all calculations performed in the new system were accurate and compliant with the terms of the original contract. It also enabled our agents to access historical data on an account including all payment and other transaction history, which is needed to perform a variety of common tasks to service our customers.
4) Customer-Centric — In the legacy system, an Ally customer with two auto loans had two separate accounts, which were not necessarily connected. In the new system, we intended to link accounts belonging to the same customer to create a better, more streamlined experience. But this required 100% confidence that the customer was indeed the same person or business entity on each account to be linked.
5) Workflow Status — The legacy mainframe was excellent at processing transactions but it didn’t have workflow capabilities to support our business process. This functionality existed in a variety of no- or low-code tools built over the course of many years. Through data migration, we needed to progress each customer service case to the appropriate step in the new system. This was complicated by the fact that our business processes were also being reengineered as part of the project to deploy the new system.
We selected Alfa Systems as the primary component of our new platform, which is a modern, market-leading asset finance solution. Alfa also served as our implementation partner, bringing experience on-boarding large and complex portfolios, such as Ally’s, to their platform. Alfa helped design our migration approach to accommodate the differences between the source and target systems, as well as other complexities, while maximizing the efficiency and accuracy of the migration.
Designing the data migration process required a relentless focus on details and a creative approach to problem solving.
We also had to be smart about defining the scope of both the migration and reconciliation. Our technology team partnered closely with the business to define the data that had to be migrated and what data elements were critical to reconcile. In some cases, the value wasn’t worth the effort, so we identified another approach. This kept the team focused on the work that was most important to a successful outcome.
Data Migration Approach
Overall, the implementation of the Ally Auto Advantage platform was a “big bang” approach wherein the entire portfolio of customers and accounts was migrated in a single deployment. This approach put data migration on the critical path for the deployment, and it was the longest single task in the implementation. Below is a simplified description of the deployment approach:
At year-end, finish processing business transactions and suspend further activity in the legacy application
Extract data from multiple source systems
Transform and stage data for the Advantage platform
Process the data in the Advantage platform
Push the migrated data and relevant updates to downstream systems
Abstract integration was used to pull required data from different legacy systems of record, including the legacy mainframe application, relational databases, and other sources. We used an approach called “Source Staging,” where all data was extracted from the source systems in its original form, pooled in a staging area, and converted into a format accepted by the target system.
High-Level Data Migration Process Flow
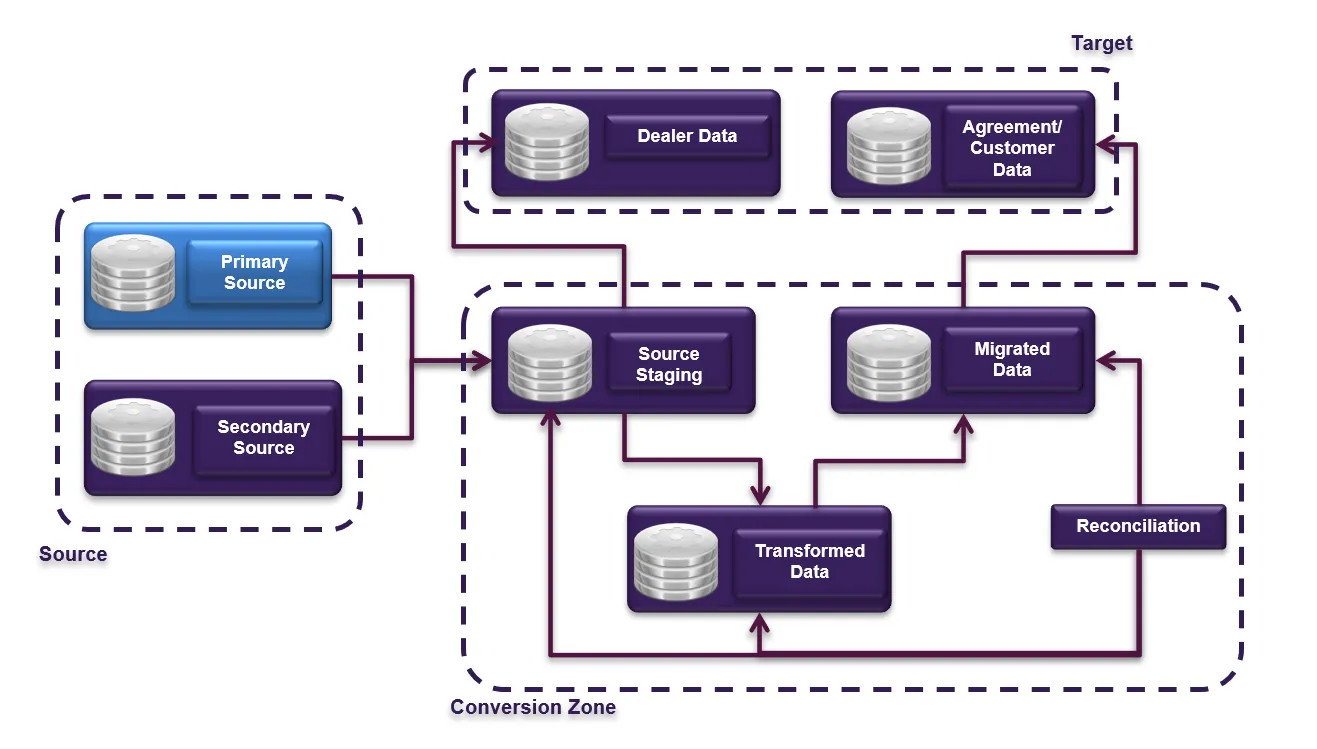
Data Migration used core database and storage features to speed the data transfer between systems. To enable continued use of the target application while the migration progressed, all migration work was performed within a controlled space referred to as the conversion zone. Standard database movement options can run for hours (and even days, depending on the data volumes). We took a storage-level snapshot to perform the data move within minutes, using the fastest hardware available, which was not our final target infrastructure. This allowed us to run other deployment activities in parallel with the data reconciliation, which occurred on the data migration hardware. This dramatically reduced the overall deployment window, which was critical for Ally’s business operations.
It’s also worth noting that we put significant effort into performance testing the migration, timing every major step in process. Because data migration was a major driver of our deployment duration, we had to ensure it was optimized. We assembled a seasoned team — including DBAs, developers, infrastructure resources, and our vendor partner — who knew how to tune our environment for optimal performance.
Data Quality, Integrity and Security
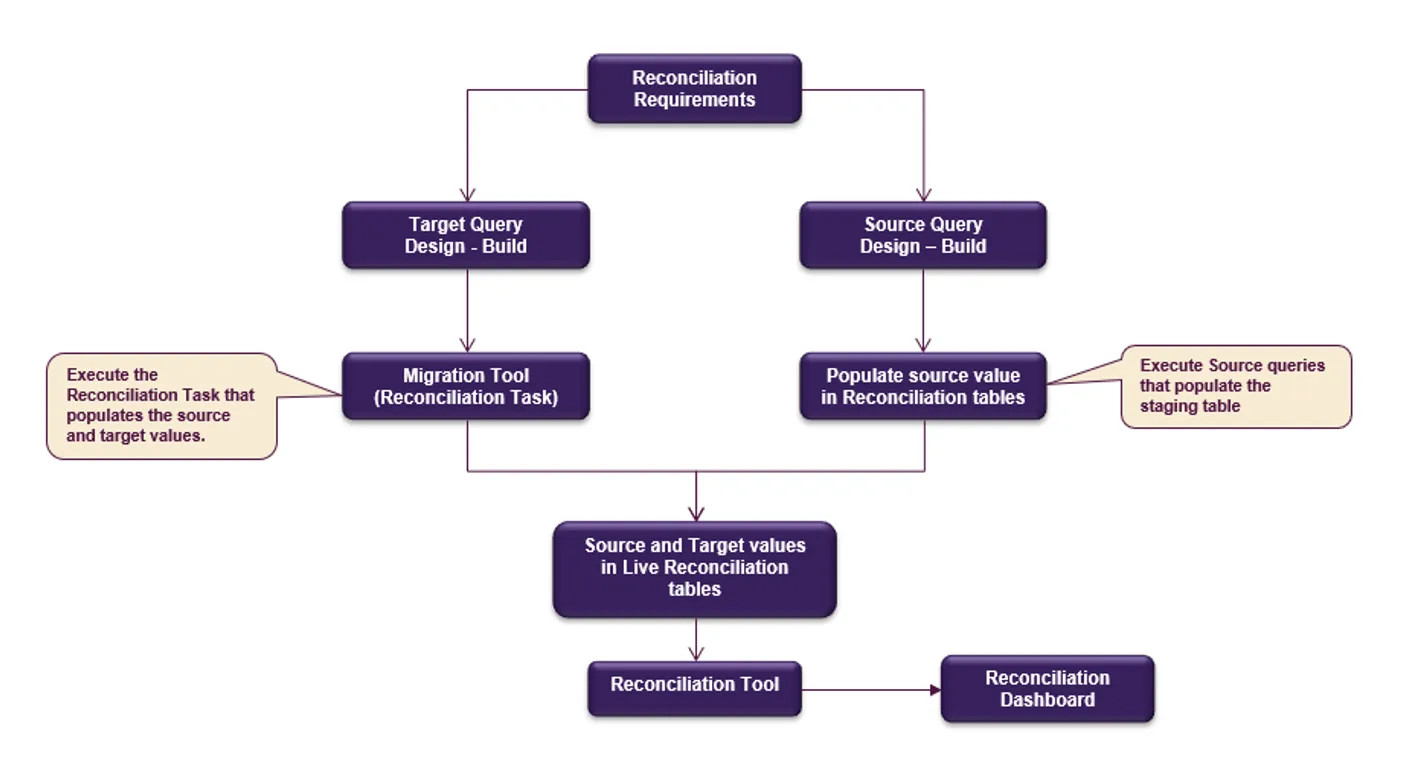
As data quality was paramount to a successful implementation, the Data Migration process was designed to maintain data integrity across all phases of the data transfer, from the source systems all the way to the final destination. This was achieved using custom-developed job sequences on ETL and the reconciliation software. The data was reconciled at the several integration points: 1) Source System to Source Staging Data Store; 2) Source Staging to the Advantage Platform; 3) Receiver tables to Live (via the Reconciliation Tool); and 4) Downstream Systems.
We defined nearly 200 reconciliation criteria to validate the data was properly transferred to the target systems over the end-to-end journey. These criteria were evaluated across 600 million rows of data during the migration process. Not all contract data elements were reconciled; our technology team worked with the business and accounting teams to identify the critical elements to reconcile, which included all monetary fields. Given the criticality of the data migration tasks, it was important to provide transparency to the progress and migration results. To accomplish this, we used analytics to compare source and target reconciliations and displayed the results on a series of dashboards as depicted by the diagram below.
As we were migrating the data from one production system to another, maintaining the security of the data was straightforward: all our normal data protection standards and protocols were in place for both systems and their respective environments, and the transmission between them.
Preparing for the Production Migration
We ran more than 20 trial migrations, most with a full-volume test data that closely represented our actual production data, with steps taken to ensure the privacy of our customer account information. These trials allowed us to validate a number of aspects, including:
The end-to-end data migration sequence
Data integrity and quality
Data migration performance and timing
Reconciliation process and related dashboards
The trials also enabled support for more efficient system and functional testing by supplying real-life test data that allowed for actual contract and customer scenarios to be tested. And, the resulting data sets proved useful for other teams needing representative test data with built-in safe-guards to comply with Ally’s strict security and privacy standards.
Lessons Learned
Throughout this journey, the team gained critical experience that can be applied to any major data migration effort. Below are a few highlights:
1) Build a Cross-Functional Team
Most critical to our successful implementation was the team we assembled for the task. We needed subject matter experts who understood the business, data definitions, accounting practices, and source/target systems. We were fortunate to have team members with prior Ally migration experience and deep understanding of the data, which gave us an early jump. Adding our implementation partner, Alfa, whose people are specialists with extensive experience migrating large portfolios to the Alfa Systems platform, and together we formed a single team with all the knowledge, skills and focus to deliver a successful data migration.
2) Start Early
Many projects start to think about data migration later in the project timeline, but we stood up our Data Migration team at the beginning. In fact, it was the first team to show data in the new application, and other teams used this data for early testing of the new application. This approach caused some rework (because Data Migration had to keep up with all changes made in the application), but we believe it was beneficial to have Data Migration running in parallel with other work-streams.
3) Prioritize Data Clean-up
Focusing on Data Migration early allowed us to spend sufficient time on data clean-up. We first developed the code to extract data from the legacy mainframe application and move it to the staging area. We then dedicated a team to assess the data and determine what had to be cleaned up and whether it had to be done in the source system or if the clean-up could occur after migration.
4) Define Clear Decision and Communication Processes
Having a clear communication process helped to make sure appropriate stakeholders were informed of the data migration status and that they understood the implications of issues and resolutions. Further, having an established decision-making process and authority helped the team get to timely and durable decisions. All decisions were documented and published to downstream teams so they could assess the impact to other systems.
5) Practice Makes Perfect
As mentioned, we completed more than 20 trial migrations. We started with a subset of the actual production data and progressed to conducting the trails with a full volume of prod data. Using full-volume data was key to our reconciliation success; if we had relied on a subset of data, we wouldn’t have been able to practice all the scenarios we encountered in the final migration. Additionally, we performed the last few trials on our final production hardware, mimicking as much as possible the actual steps that were to occur in the production deployment. This helped us to catch and correct a few environment-specific issues prior to the start of deployment.
Interested in joining Ally's team of talented technologists to make a difference for our customers and communities? Check outAlly Careersto learn more.